特定のファイル一覧を出力するときのメモ
2020年06月20日 プログラミングTIPS
Linuxサーバー内のある特定のファイルの一覧を出力したくなりました。例えば、「*.html」とか「*.php」とかです。Linuxにはtreeコマンドがあったなと思ってCentOS8で打とうとしたらありませんでした。ということで、まずはtreeコマンドのインストールから。CentOS8ではインストールコマンドが今までの「yum」から「dnf」に変わっています(「yum」でも動きます)。
ディレクトリの情報はいらなくて、全ての階層のサブディレクトリまでファイルパスとファイル名だけ出てきてくれれば良かったので、「.html」のファイルを全て出力するために以下のようなコマンドを打ってみました。
これでファイル一覧がhtml_list.txtに出力されるかと思ったら、htmlファイルだけでなくディレクトリ情報も一緒に出力されてしまいました。
ファイルだけをスマートに出力させたかったのですが、できていなかった上にもうローカルにダウンロードしてしまったので、今度は特定のファイルを含まない行を全て削除する方法を考えてみました。
今使っているWindows用のエディタ「Sublime Text」は複数行置換や正規表現などに対応していて高機能です。それならと、「特定の文字列を含まない行」を置換できるのではないかと考えました。探してみたらすぐ見つかりました。
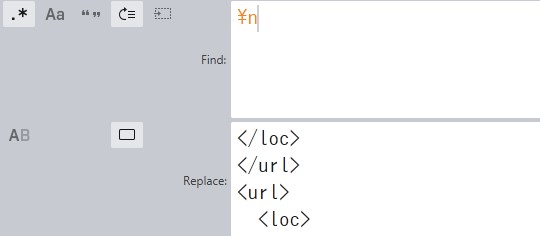
Sublime Textで「特定の文字列を含まない行」は以下のようにして取り出せます。
「html以外の行を削除」というのであれば、Sublime Text3で正規表現置換をONにして、以下のように置換すればOKです(置換後の文字列は空白です)。
これで、「html」で終わっているファイルを全て取り出せました。ファイルパスは相対パスになっているため、ここからドメイン名に置換すると、そのまますべてのhtmlファイルのURLになります。sitemapで静的なhtmlファイルの一覧を作るときに、この方法を使いました。
ついでに、sitemapは一般的に以下のような構造になっています。
出力した全てのHTMLファイルのパスが一行ずつ並んでいるのなら…
dnf install treeディレクトリの情報はいらなくて、全ての階層のサブディレクトリまでファイルパスとファイル名だけ出てきてくれれば良かったので、「.html」のファイルを全て出力するために以下のようなコマンドを打ってみました。
tree -f -i ./ -P '*.html' > html_list.txtファイルだけをスマートに出力させたかったのですが、できていなかった上にもうローカルにダウンロードしてしまったので、今度は特定のファイルを含まない行を全て削除する方法を考えてみました。
今使っているWindows用のエディタ「Sublime Text」は複数行置換や正規表現などに対応していて高機能です。それならと、「特定の文字列を含まない行」を置換できるのではないかと考えました。探してみたらすぐ見つかりました。
Sublime Textで「特定の文字列を含まない行」は以下のようにして取り出せます。
^(?!.*文字列).+$^(?!.*html).+$\nついでに、sitemapは一般的に以下のような構造になっています。
<url>
<loc></loc>
<priority></priority>
<changefreq></changefreq>
<lastmod></lastmod>
</url>出力した全てのHTMLファイルのパスが一行ずつ並んでいるのなら…
上記のようにSublime Textで複数行置換することによって、簡易的な(priority、lastmod、changefreqの情報を持たない)サイトマップを作れます。詳しい情報は持たず、とりあえずURLを羅列しただけのHTMLファイルのサイトマップを作りたいときに使えます。
treeコマンドを使わず、Linux上でスマートに出力させる方法を考えた方が良かったのかもしれませんが、とりあえず目的は達成できたのでよしとします。
「grepはファイル内の文字列を調べるので、リッチすぎるのでは?」と思って手を出していませんでした。grepをオススメされたので、grepでファイル一覧を取り出す方法について考えてみました。全てのサブディレクトリまでのhtmlファイルを取り出すために、以下のオプションを付けることにしました。
これで、今いるディレクトリ以下にある全ての「ファイル内にhtmlの文字列がある.htmlファイル」の一覧を出力できました。検索する対象のファイル拡張子が決まっているのなら、grepを使った方がスマートでした。
「-type f」でディレクトリを除外してファイル限定、「-name "*\.html"」で.htmlが含まれるファイル限定にしています。そのまま出力すると順番がバラバラなので、「| sort」で名前順にしています。ディレクトリ以下の特定の拡張子ファイル一覧を取り出したいときはこのコマンドでOKですね。
ファイル内の文字列までチェックして一覧を取り出したい場合はgrepで、ファイル名だけで一覧を取り出したい場合はfindで。一つ賢くなりました。
treeコマンドを使わず、Linux上でスマートに出力させる方法を考えた方が良かったのかもしれませんが、とりあえず目的は達成できたのでよしとします。
追記1:grepで出力
Twitterでgrepを使った方法についてアドバイスいただきました。grep -P (Perl正規表現) をtreeの出力にパイプで繋げると良いすよ
— 桔梗(キキョウ) (@bellflower2015) June 20, 2020
「grepはファイル内の文字列を調べるので、リッチすぎるのでは?」と思って手を出していませんでした。grepをオススメされたので、grepでファイル一覧を取り出す方法について考えてみました。全てのサブディレクトリまでのhtmlファイルを取り出すために、以下のオプションを付けることにしました。
- -i(--ignore-case)
- 大文字小文字を区別しない
- -r(--recursive)
- サブディレクトリ内も再帰的に検索する
- --include
- 特定の拡張子のみ対象にする
grep -irl --include='*.html' html ./* > html_list.txt追記2:findで出力
grepでファイル内まで検索するマジメな検索方法を考えたので、ついでにfindで検索してみる方法も考えてみました。本当はこれを最初にやるべきでしょう。find -type f -name "*\.html" | sort > html_list.txtファイル内の文字列までチェックして一覧を取り出したい場合はgrepで、ファイル名だけで一覧を取り出したい場合はfindで。一つ賢くなりました。